

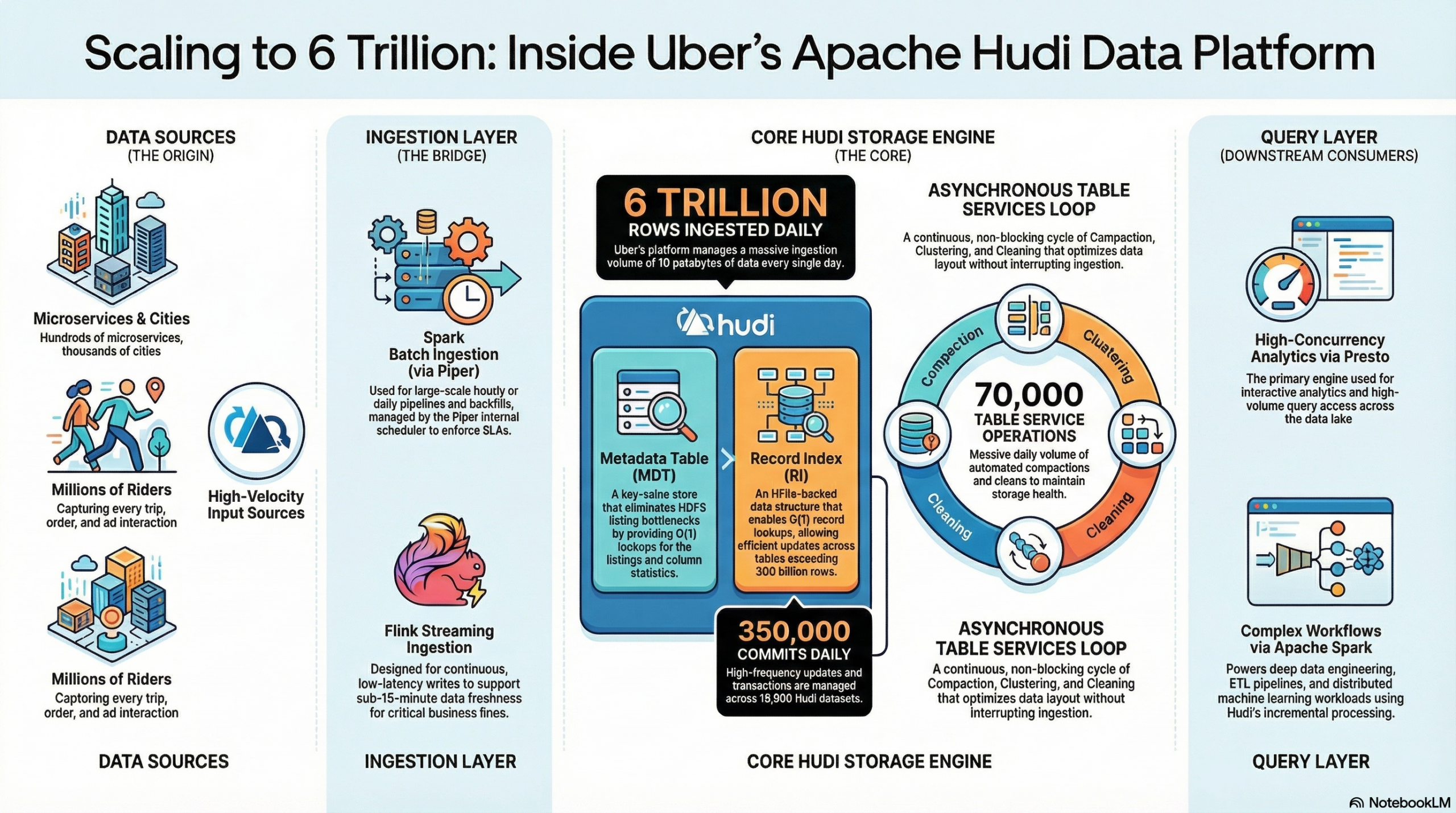
In the world of data engineering, “scale” is often a relative term. But at Uber, scale means managing a multi-hundred-petabyte repository that handles 6 trillion rows ingested daily. To manage this tidal wave of information, Uber moved away from traditional append-only data lakes to create Apache Hudi™, a storage engine that brings database-like primitives to the lake.
This post explores the technical architecture and workflows that allow Uber to maintain data freshness and consistency at one of the largest centralized data lakes on the planet.
——————————————————————————–
1. The Numbers Behind the Machine
To appreciate the engineering, you first have to understand the sheer magnitude of Hudi’s footprint at Uber:
- 19,500 Hudi datasets across domains like mobility, delivery, and safety.
- 350 logical petabytes stored on HDFS™ and Google Cloud Storage.
- 10 petabytes ingested daily, with 3 petabytes written to the lake every 24 hours.
- 350,000 commits and 70,000 table service operations (compaction, cleaning, clustering) daily.
- 4 million analytical queries served weekly via Presto® and Apache Spark™.
——————————————————————————–
2. The Complete Technical Workflow
Uber’s data platform is a deeply interconnected stack where Hudi acts as the foundational storage orchestrator.
Step 1: Ingestion (Spark & Flink)
- Spark Batch Ingestion: Used for large-scale hourly/daily pipelines and backfills. Uber uses an internal scheduler called Piper to manage these DAGs and enforce SLAs.
- Flink Streaming Ingestion: To achieve sub-15-minute freshness, Uber is shifting to Flink-native streaming. This allows for continuous, low-latency writes that support real-time business lines.
Step 2: Storage & Indexing (The Hudi Magic)
As data enters the lake, Hudi uses specialized primitives to manage it:
- ACID Transactions: Ensures correctness even if pipelines overlap or fail.
- Record Index (RI): This is a native, HFile-backed data structure that maps record keys to file groups. It enables O(1) lookups with a latency of just 1-2 milliseconds, even in tables exceeding 300 billion rows.
- Metadata Table (MDT): Instead of overwhelming the HDFS NameNode with file listings, Hudi uses the MDT (an SSTable-based key-value store) to track file locations and column statistics, making folder listings an O(1) operation.
Step 3: Table Services
To keep queries fast, Hudi runs asynchronous Table Services:
- Compaction: Merges small files and updates.
- Clustering: Reorganizes data layout for better query performance.
- Cleaning: Removes older versions of data to save space.
Step 4: Querying & Analytics
- Apache Spark: Used for complex ETL, feature engineering, and ML workloads.
- Presto: The go-to engine for high-concurrency, interactive analytics.
- Incremental Processing: One of Hudi’s biggest advantages is allowing engines to read only what changed since the last commit, avoiding expensive full-table scans.
——————————————————————————–
3. Specialized Workload Classes
Uber categorizes its 19,500+ datasets into four classes, each tuned for specific performance:
- Append-Only (11,200 tables): Raw logs using Hudi’s bulk insert for high-volume throughput.
- Upsert-Heavy (4,400 tables): Tables modeling changing states (like a trip life cycle) that require frequent row-level updates.
- Derived (1,600 tables): Tables created via transformations of raw data, often using Hudi Streamer for incremental updates.
- Real-time (500 tables): Flink-native tables designed for the highest throughput and lowest latency.
——————————————————————————–
4. Engineering for Resilience
At this scale, failures are inevitable. Uber ensures reliability through:
- HiveSync: A multi-data-center design that maintains a primary and a replicated secondary dataset. Intelligent query routing directs reads to the healthiest region during failovers.
- Observability: All operations emit M3-based metrics. The Hudi Validation tool is used to detect silent issues like file corruption before they cascade.
- Schema Evolution: Automated validation ensures that “backwards-incompatible” changes (like column renames) don’t break thousands of downstream jobs.
Conclusion
Uber’s journey with Hudi proves that at trillion-record scale, you cannot treat the data lake as passive file storage. By building a disciplined operational ecosystem around ACID transactions and high-performance indexing, Uber has bridged the gap between streaming runtimes and massive-scale storage.
As the platform moves toward Hudi 1.x, the focus remains on modernizing legacy APIs and scaling real-time capabilities to handle the next decade of data growth