
How Hash Tables Silently Help Modern Database Engines Join Tables Under the Hood
When developers write a SQL query like:
SELECT *
FROM Orders o
JOIN Customers c
ON o.customer_id = c.customer_id;it looks simple.
But behind the scenes, the database engine may process millions — sometimes billions — of rows.
So how does it perform these joins so quickly?
The answer is often a powerful data structure working silently underneath:
The Hash Table
Most modern database engines such as PostgreSQL, MySQL, Microsoft SQL Server, and Oracle Database use Hash Joins internally to speed up joins dramatically.
The Problem With Naive Table Joins
Imagine two tables:
Customers
| customer_id | name |
|---|---|
| 101 | John |
| 102 | Alice |
| 103 | David |
Orders
| order_id | customer_id |
|---|---|
| 1 | 101 |
| 2 | 103 |
| 3 | 102 |
A naive approach would compare every row from Orders with every row from Customers.
That means:
Orders rows × Customers rowsThis becomes extremely expensive for large datasets.
For example:
- 1 million orders
- 1 million customers
Could mean:
1,000,000 × 1,000,000 comparisons
= 1 trillion operationsClearly not scalable.
Enter the Hash Table
A hash table solves this lookup problem beautifully.
Instead of repeatedly scanning the customer table, the database creates an in-memory lookup structure.
Conceptually:
{
101: "John",
102: "Alice",
103: "David"
}Now finding customer 101 is nearly instant.
Instead of searching linearly:
O(n)lookup becomes approximately:
O(1)This changes everything.
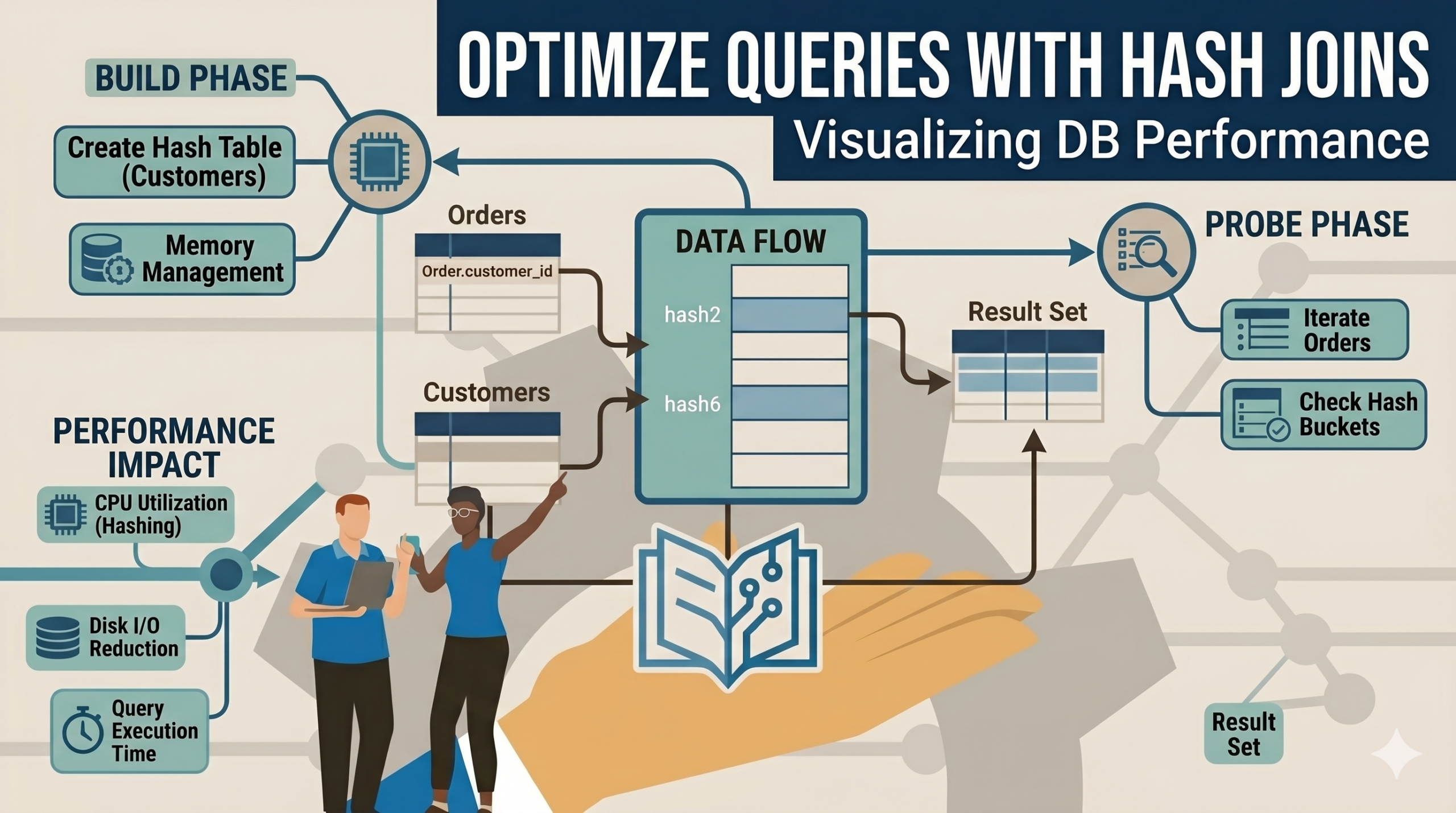
How Hash Join Works Internally
Modern database engines usually perform a Hash Join in two phases.
Phase 1 — Build Phase
The database reads the smaller table first.
Example:
Customers TableIt builds a hash table using the join key:
customer_idInternally:
Hash(101) → John
Hash(102) → Alice
Hash(103) → DavidNow the database has a super-fast lookup structure in memory.
Phase 2 — Probe Phase
The engine scans the second table:
OrdersFor each order row:
customer_id = 101it computes the hash and instantly checks the hash table.
Hash(101) → Match FoundBoom — join completed.
No full-table scanning required.
Real-World Example
Imagine an e-commerce company:
- 500 million orders
- 50 million customers
Without optimized joins, analytics queries could take hours.
With hash joins:
- Customer records are hashed once
- Orders probe the hash table rapidly
- Queries finish in minutes or seconds
This is one reason modern data warehouses scale efficiently.
Platforms like Snowflake, Apache Spark, and Databricks heavily rely on hash-based processing internally.
The next time you write a JOIN query, remember:
You’re not just writing SQL.
You’re triggering sophisticated algorithms optimized over decades of database engineering.
And somewhere deep inside the engine…
a hash table is doing the heavy lifting.